KL Diversion & JS Diversion
简介
KL散度和JS散度本质上都是用于用来衡量两个分布之间的差异的值,并且分别具有一些不一样的性质,并且通常它们分别对应用于解决一些不一样的实际问题。
这篇文章从信息论和熵为起点,展开对 KL Diversion 和 JS Diversion 的介绍。
1 信息论
自信息量定义:
对于事件集合X={x1,x2…xn},其中某一事件xi发生的概率为pi,则自信息量定义为:
I(xi)=−logpi
(通常log底数取2,单位为bit)
自信息的理解
对于自信息这个概念,可从多个角度来理解:
- 表示事件不确定性的大小;
- 表示事件发生带来信息量的多少,事件一旦发生,就消除了不确定性,从而带来了信息量;
- 表示为了确定事件的发生,所需信息量的多少。
2 熵
熵,又叫平均自信息,数学定义如下:
H(X)=E(I(xi))=−i=1∑npilogpi
熵的理解
同样可以从多种角度理解熵的概念:
- 随机变量不确定性的大小
- 观测这个随机变量得到平均信息量的大小
- 确定这个随机变量取值所需的平均信息量大小
- 系统的凌乱程度
3 Divsersion
在机器学习中,p往往用来表示样本的真实分布,q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
3.1 KL Diversion(相对熵)
Kullback-Leibler Diversion的作用:用分布q描述分布p时损失的信息量的大小。
KL散度只是对我们的熵公式的略微修改,考虑概率分布p及近似分布q。并且查看log值的差异:
DKL(p∥q)=i=1∑Np(xi)(logp(xi)−logq(xi))
本质上,我们用KL散度观察原始分布与近似分布之间的对数差的期望。
KL Diversion公式的改写
如果我们考虑log2,我们可以将其解释为“我们预计有多少比特位的信息丢失”,我们可以根据期望重写公式:
DKL(p∥q)=E[logp(xi)−logq(xi)]
3.2 Cross Entropy(交叉熵)
DKL(p∥q)=∑i=1np(xi)log(q(xi)p(xi))=∑i=1np(xi)log(p(xi))−∑i=1np(xi)log(q(xi))=−H(p(x))+[−∑i=1np(xi)log(q(xi))]
上述公式是对KL散度公式的整理,发现 KL散度=P的熵+交叉熵 。
因此在分类任务中,由于P的熵是定值,所以在一般的任务直接使用交叉熵作为Loss即可。
3.3 JS Diversion
JS散度度量了两个概率分布的相似度,是基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。定义如下:
JS(P1∥P2)=21KL(P1∥2P1+P2)+21KL(P2∥2P1+P2)
JS Diversion的python实现
def JensenShannonDivergence(p, q):
p = np.array(p)
q = np.array(q)
M = (p + q)/2
return 0.5 * np.sum(p*np.log(p/M)) + 0.5 * np.sum(q*np.log(q/M))
3.4 Wasserstein距离
待更新。。。
4 参考资料
https://zhuanlan.zhihu.com/p/523745054open in new window——信息论
https://zhuanlan.zhihu.com/p/74075915open in new window——四种熵值
https://zhuanlan.zhihu.com/p/100676922open in new window——KL Diversion
https://zhuanlan.zhihu.com/p/34998569open in new window——当你对VAE中的知识有点模糊的时候可以回顾这篇文章
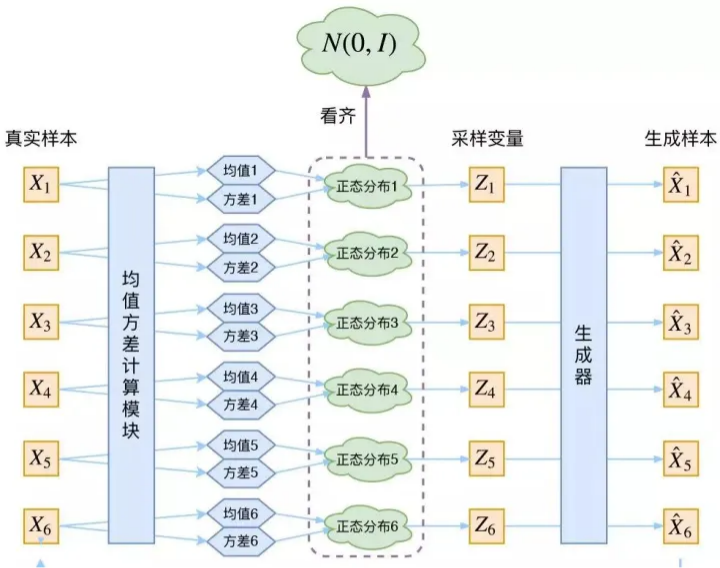
5 VAE-Model示意图