
Self_Attention
大约 2 分钟
Attention机制
相关信息
个人理解注意力机制是一种特殊的全连接层,其中一共有若干个(多头)Wq,Wk,Wv三个矩阵作为注意力参数(每一个矩阵大小都是n特征维数的平方)
1 Self-attention
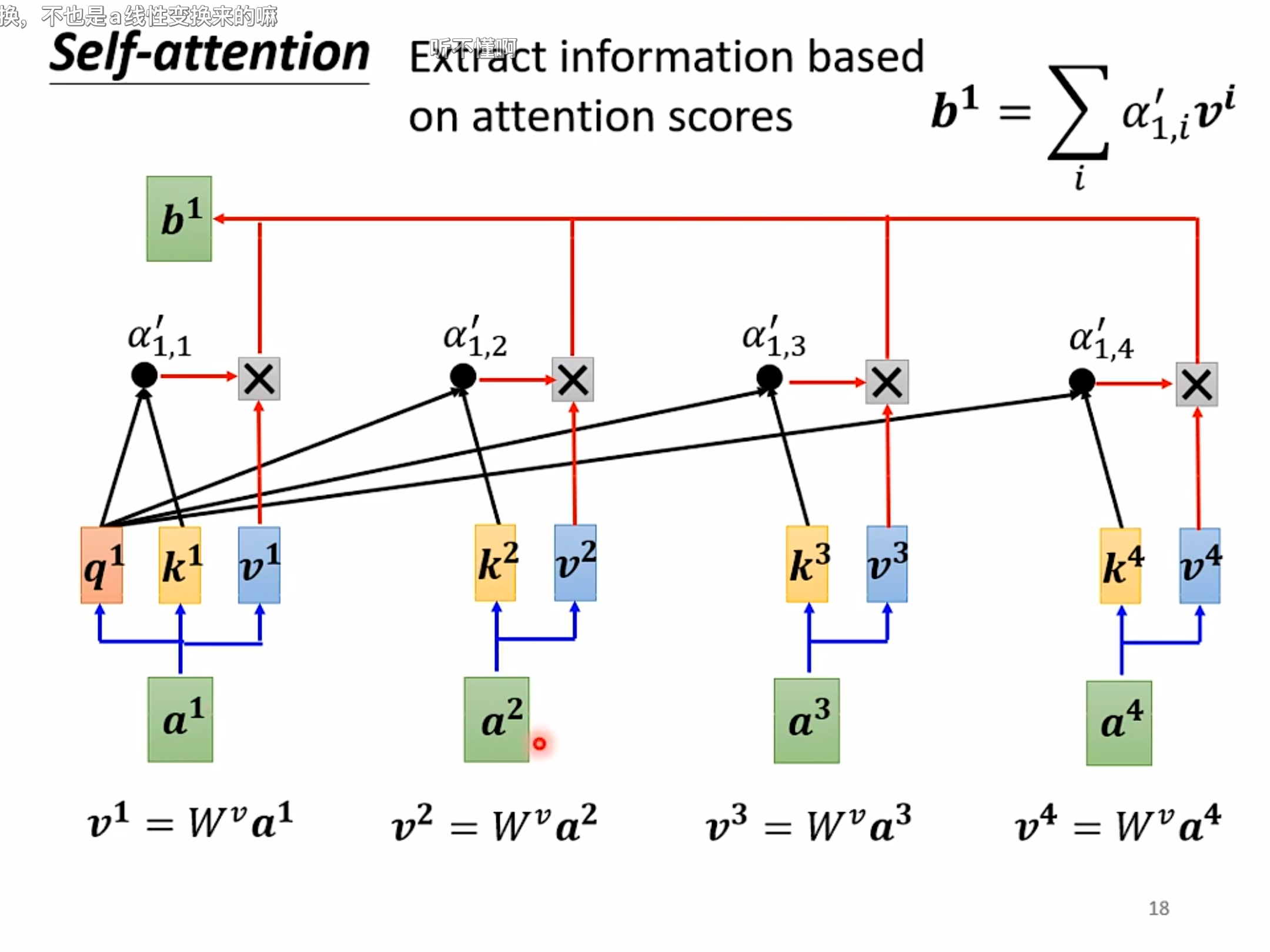
以a1得到b1为例讲解注意力机制:
attention计算过程
- a1通过叉乘Wq得到q1,即为query;
- 【a1, a2, a3, ...】通过点乘Wk得到【k1, k2, k3, ...】,即为各个an的key;
- 【a1, a2, a3, ...】通过点乘Wv得到【v1, v2, v3, ...】,即为各个an的value;
- 将q1(即 a1的query)点乘各个kn(即an的key),通常会再经过一个SoftMax层,最终得到a'1,n(即a1对an的Attention Score);
- 最后一步用a1的注意力分数叉各个value,求和得到b1,公式如下:
 :::
:::
2 Multi-head Self-attention
多头注意力机制其实和注意力机制相似,通过设定多个Wq,Wk,Wv矩阵以捕获不同的关系(学习不同类型的注意力),因此最终可以得到多个bi,可以通过一个新的矩阵W0将【bi,1,bi,2,bi,3, ...】整合成一个包含多个注意力信息的输出bi。
3 Positional Encoding
Positional Encoding:https://arxiv.org/abs/2003.09229
Transformer:https://arxiv.org/abs/1706.03762
BERT:https://arxiv.org/abs/1810.04805
4 Cross attention
Cross attention同时也是Transformer中decoder所采用的架构,一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V。
4 补充:SoftMax 以及 Cross Entropy
Soft:并非强硬地输出最大值
Max:求最大值
通过SoftMax不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性,计算公式如下:
其中为第i个节点的输出值,C为输出节点的个数,即分类的类别个数。通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布.
当使用Softmax函数作为输出节点的激活函数的时候,一般使用交叉熵作为损失函数。