
CODE-AE
文献阅读(1)CODE-AE
标题:A context-aware deconfounding autoencoder for robust prediction of personalized clinical drug response from cell-line compound screening**
1 亮点
- CODE-AE既可提取不同样本间的共享生物信号,也可以提取它们特有的私有生物信号,从而分离出数据模式之间的混杂因素;
- CODE-AE通过将药物反应信号与混杂因素分离,进而实现局部对齐(大多方法只能实现在全局上的对齐)。
2 模型示意图
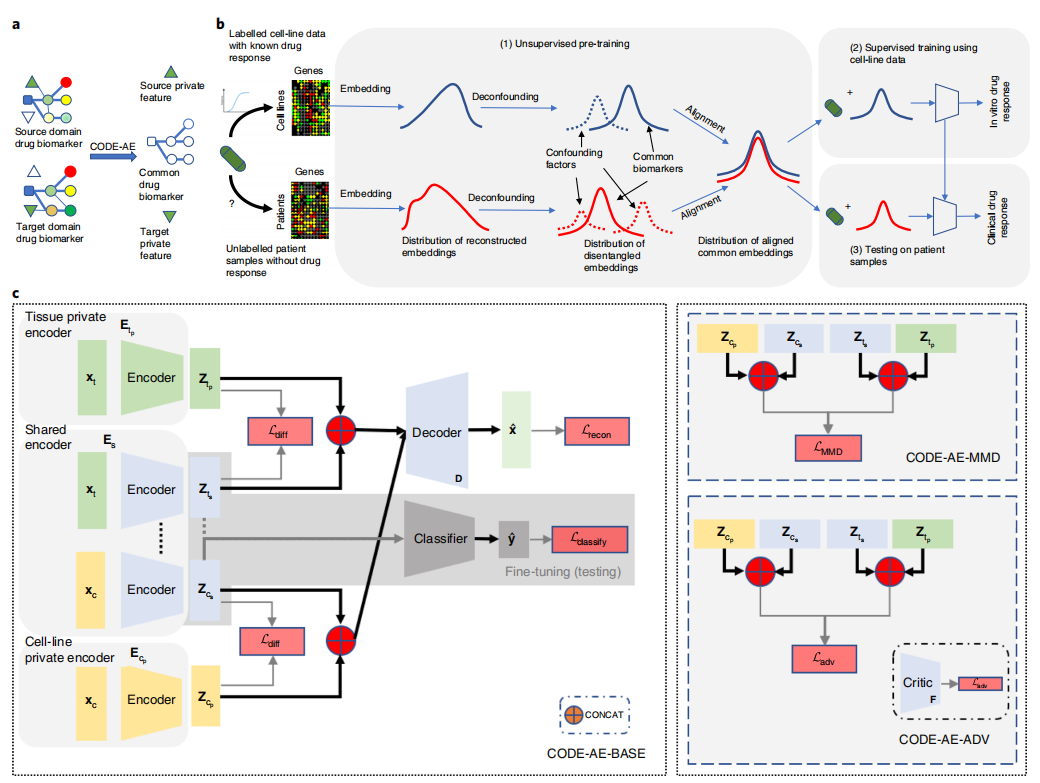
2.1 预训练
在预训练阶段,使用无监督学习方法将Cell Line和Patient的基因表达矩阵映射到一个隐空间中,并且将生物混杂因素从其中分离出来,使得Patient的分布与Cell Line的分布相一致,以消除系统偏差(例如,批处理效应)。
2.2 微调
在微调阶段,在预训练好的CODE-AE中添加一个监督模型,并使用标记的Cell Line药物反应数据对细胞系进行进行训练。
2.3 推理
在推理阶段,首先从预训练好的CODE-AE中获得患者的embedding,再通过第二阶段微调好的模型来预测患者对药物的反应。
3 实验内容
3.1 基础实验——映射效果(⭐)
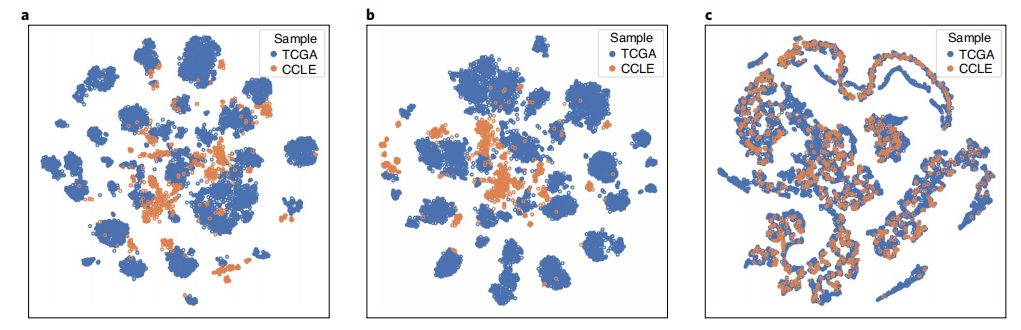
a. 原始表达;b.标准ae;c. CODE-AE-ADV
3.2 消除生物变量
当应用从男性数据中训练出来的模型来预测女性癌症亚型时,CODE-AE-ADV的表现略低于CORAL,但差异没有统计学意义。
3.3 CODE-AE改善了对体外药物反应的预测
评估CODE-AE-ADV是否可以使用Cell Line训练好的模型预测患者对新化合物的特异性反应。
使用了来自PDTC的体外药物反应数据:图为47个药物作用在体外患者上的效果与预测结果的AUROC和AUPRC值的情况。
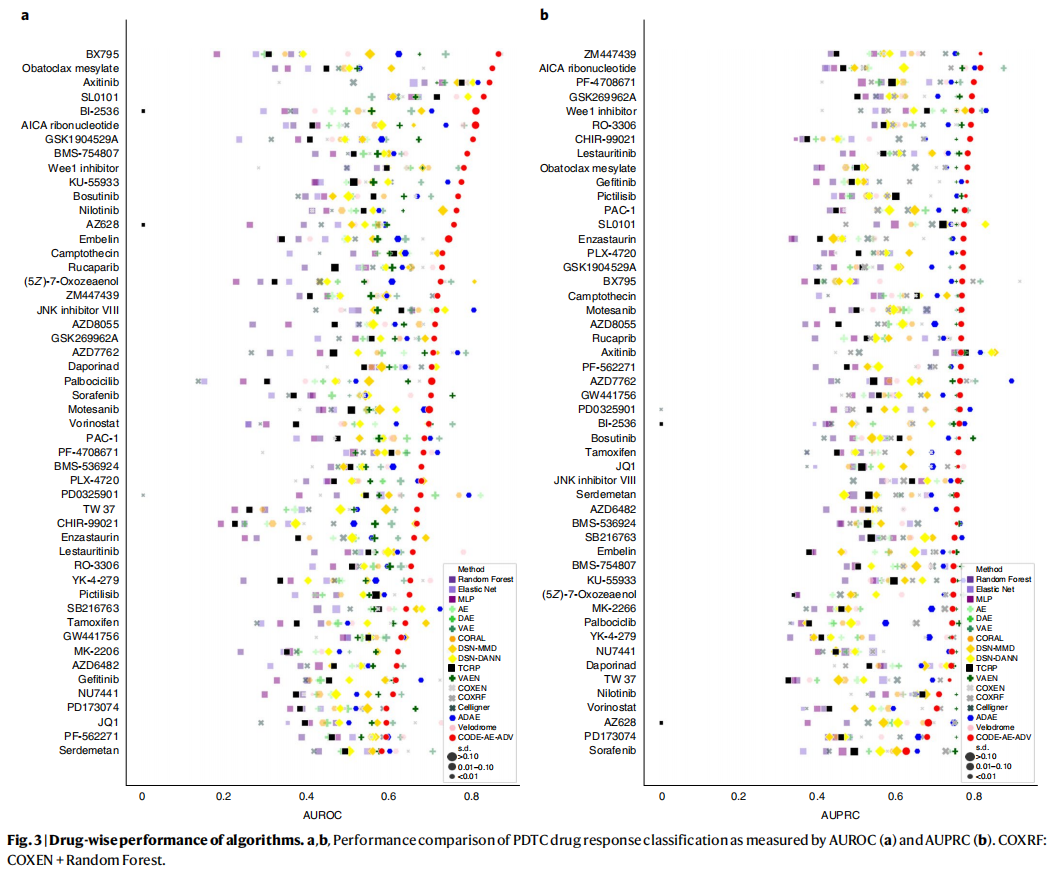
3.4 CODE-AE-ADV在个性化医疗中的应用
4 方法
4.1 CODE-AE-BASE
MODEL
Loss
4.2
5 代码
5.1 目录结构🌳
服务器:/home/hht/Myapps/Transfer_Project/Repeat_CODE_AE/CODE-AE-main/
doc_tree
.
├── code
│ ├── adae_hyper_main.py
│ ├── ae.py
│ ├── base_ae.py
│ ├── data_config.py
│ ├── data_preprocessing.py
│ ├── data.py
│ ├── Dockerfile
│ ├── drug_ft_hyper_main.py
│ ├── drug_inference_main.py
│ ├── dsn_ae.py
│ ├── encoder_decoder.py
│ ├── evaluation_utils.py
│ ├── fine_tuning.py
│ ├── generate_encoded_features.py
│ ├── generate_plots.ipynb
│ ├── gradient_reversal.py
│ ├── inference.py
│ ├── loss_and_metrics.py
│ ├── ml_baseline.py
│ ├── mlp_main.py
│ ├── mlp.py
│ ├── model_save
│ ├── parsing_utils.py
│ ├── pretrain_hyper_main.py
│ ├── reproduce_fig4.py
│ ├── tcrp_main.py
│ ├── train_adae.py
│ ├── train_ae.py
│ ├── train_code_adv.py
│ ├── train_code_base.py
│ ├── train_code_mmd.py # 详细介绍
│ ├── train_coral.py
│ ├── train_dae.py
│ ├── train_dsna.py
│ ├── train_dsn.py
│ ├── train_dsnw.py
│ ├── train_vae.py
│ ├── types_.py
│ ├── vaen_main.py
│ └── vae.py
├── data
│ ├── pdtc_gdsc_drug_mapping.csv
│ └── tcga_gdsc_drug_mapping.csv
├── figs
│ └── architecture.png
├── intermediate_results
│ ├── encoded_features
│ ├── plot_data
│ └── tcga_prediction
├── LICENSE
└── README.md
5.2 train_code_mmd.py
其中一共包含三个函数:
eval_dsnae_epoch():接受四个参数,通过传入model与dataloader,返回添加了最新损失的训练记录history{'loss': [loss], 'recons_loss': [recons_loss], 'ortho_loss': [ortho_loss]}
dsn_ae_train_step():接受八个参数,通过传入两个模型s_dsnae,t_dsnae,batch,optimizer,返回添加了最新损失的训练记录history{'loss': [loss], 'recons_loss': [recons_loss], 'ortho_loss': [ortho_loss], 'mmd_loss': [mmd_loss]}
train_code_mmd() :传入dataloader即可,函数内实现s_dsnae和t_dsnae的实例化,通过调用上述两个函数==eval_dsnae_epoch()和dsn_ae_train_step()==训练code_mmd
train_code_mmd.py
import os
from itertools import chain
from dsn_ae import DSNAE
from evaluation_utils import *
from mlp import MLP
from loss_and_metrics import mmd_loss
from collections import OrderedDict
def eval_dsnae_epoch(model, data_loader, device, history):
"""
对DSNAE模型进行一轮评估,计算损失并更新历史记录。
总的来说,接受四个参数:model, data_loader, device, history,然后输出更新后的history字典
:param model: DSNAE模型
:param data_loader: 数据集的数据加载器
:param device: 训练设备
:param history: 历史记录字典
:return: 更新后的历史记录字典
"""
model.eval()
# 定义损失的平均值字典
avg_loss_dict = defaultdict(float)
for x_batch in data_loader:
x_batch = x_batch[0].to(device)
with torch.no_grad():
loss_dict = model.loss_function(*(model(x_batch)))
for k, v in loss_dict.items():
avg_loss_dict[k] += v.cpu().detach().item() / len(data_loader)
for k, v in avg_loss_dict.items():
history[k].append(v)
return history
def dsn_ae_train_step(s_dsnae, t_dsnae, s_batch, t_batch, device, optimizer, history, scheduler=None):
"""
:param s_dsnae: 源域编码器模型
:param t_dsnae: 目标域编码器模型
:param s_batch: 源域batch
:param t_batch: 目标域batch
:param device: 训练设备
:param optimizer: 优化器
:param history: 历史记录字典
:param scheduler: 可选的学习率调度器
:return:
"""
s_dsnae.zero_grad()
t_dsnae.zero_grad()
s_dsnae.train()
t_dsnae.train()
s_x = s_batch[0].to(device)
t_x = t_batch[0].to(device)
s_code = s_dsnae.encode(s_x)
t_code = t_dsnae.encode(t_x)
s_loss_dict = s_dsnae.loss_function(*s_dsnae(s_x))
t_loss_dict = t_dsnae.loss_function(*t_dsnae(t_x))
optimizer.zero_grad()
m_loss = mmd_loss(source_features=s_code, target_features=t_code, device=device)
loss = s_loss_dict['loss'] + t_loss_dict['loss'] + m_loss
loss.backward()
optimizer.step()
if scheduler is not None:
scheduler.step()
loss_dict = {k: v.cpu().detach().item() + t_loss_dict[k].cpu().detach().item() for k, v in s_loss_dict.items()}
for k, v in loss_dict.items():
history[k].append(v)
history['mmd_loss'].append(m_loss.cpu().detach().item())
return history
def train_code_mmd(s_dataloaders, t_dataloaders, **kwargs):
"""
:param s_dataloaders: 源域数据加载器,元组类型,第一个元素为训练集数据加载器,第二个元素为测试集数据加载器
:param t_dataloaders: 目标域数据加载器,元组类型,第一个元素为训练集数据加载器,第二个元素为测试集数据加载器
:param kwargs: 其他可选参数,字典类型
:return: 共享编码器和训练历史记录
"""
s_train_dataloader = s_dataloaders[0]
s_test_dataloader = s_dataloaders[1]
t_train_dataloader = t_dataloaders[0]
t_test_dataloader = t_dataloaders[1]
# 初始化共享编码器和解码器
shared_encoder = MLP(input_dim=kwargs['input_dim'],
output_dim=kwargs['latent_dim'],
hidden_dims=kwargs['encoder_hidden_dims'],
dop=kwargs['dop']).to(kwargs['device'])
shared_decoder = MLP(input_dim=2 * kwargs['latent_dim'],
output_dim=kwargs['input_dim'],
hidden_dims=kwargs['encoder_hidden_dims'][::-1],
dop=kwargs['dop']).to(kwargs['device'])
# 初始化源域和目标域的私有编码器
s_dsnae = DSNAE(shared_encoder=shared_encoder,
decoder=shared_decoder,
alpha=kwargs['alpha'],
input_dim=kwargs['input_dim'],
latent_dim=kwargs['latent_dim'],
hidden_dims=kwargs['encoder_hidden_dims'],
dop=kwargs['dop'],
norm_flag=kwargs['norm_flag']).to(kwargs['device'])
t_dsnae = DSNAE(shared_encoder=shared_encoder,
decoder=shared_decoder,
alpha=kwargs['alpha'],
input_dim=kwargs['input_dim'],
latent_dim=kwargs['latent_dim'],
hidden_dims=kwargs['encoder_hidden_dims'],
dop=kwargs['dop'],
norm_flag=kwargs['norm_flag']).to(kwargs['device'])
# 获取训练设备
device = kwargs['device']
dsnae_train_history = defaultdict(list)
dsnae_val_history = defaultdict(list)
if kwargs['retrain_flag']:
ae_params = [t_dsnae.private_encoder.parameters(),
s_dsnae.private_encoder.parameters(),
shared_decoder.parameters(),
shared_encoder.parameters()
]
ae_optimizer = torch.optim.AdamW(chain(*ae_params), lr=kwargs['lr'])
for epoch in range(int(kwargs['train_num_epochs'])):
if epoch % 50 == 0:
print(f'AE training epoch {epoch}')
for step, s_batch in enumerate(s_train_dataloader):
t_batch = next(iter(t_train_dataloader))
dsnae_train_history = dsn_ae_train_step(s_dsnae=s_dsnae,
t_dsnae=t_dsnae,
s_batch=s_batch,
t_batch=t_batch,
device=device,
optimizer=ae_optimizer,
history=dsnae_train_history)
dsnae_val_history = eval_dsnae_epoch(model=s_dsnae,
data_loader=s_test_dataloader,
device=device,
history=dsnae_val_history
)
dsnae_val_history = eval_dsnae_epoch(model=t_dsnae,
data_loader=t_test_dataloader,
device=device,
history=dsnae_val_history
)
for k in dsnae_val_history:
if k != 'best_index':
dsnae_val_history[k][-2] += dsnae_val_history[k][-1]
dsnae_val_history[k].pop()
save_flag, stop_flag = model_save_check(dsnae_val_history, metric_name='loss', tolerance_count=50)
if kwargs['es_flag']:
if save_flag:
torch.save(s_dsnae.state_dict(), os.path.join(kwargs['model_save_folder'], 'm_s_dsnae.pt'))
torch.save(t_dsnae.state_dict(), os.path.join(kwargs['model_save_folder'], 'm_t_dsnae.pt'))
if stop_flag:
break
if kwargs['es_flag']:
s_dsnae.load_state_dict(torch.load(os.path.join(kwargs['model_save_folder'], 'm_s_dsnae.pt')))
t_dsnae.load_state_dict(torch.load(os.path.join(kwargs['model_save_folder'], 'm_t_dsnae.pt')))
torch.save(s_dsnae.state_dict(), os.path.join(kwargs['model_save_folder'], 'm_s_dsnae.pt'))
torch.save(t_dsnae.state_dict(), os.path.join(kwargs['model_save_folder'], 'm_t_dsnae.pt'))
else:
try:
if kwargs['norm_flag']:
loaded_model = torch.load(os.path.join(kwargs['model_save_folder'], 'm_t_dsnae.pt'))
new_loaded_model = {key: val for key, val in loaded_model.items() if key in t_dsnae.state_dict()}
new_loaded_model['shared_encoder.output_layer.0.weight'] = loaded_model[
'shared_encoder.output_layer.3.weight']
new_loaded_model['shared_encoder.output_layer.0.bias'] = loaded_model[
'shared_encoder.output_layer.3.bias']
new_loaded_model['decoder.output_layer.0.weight'] = loaded_model['decoder.output_layer.3.weight']
new_loaded_model['decoder.output_layer.0.bias'] = loaded_model['decoder.output_layer.3.bias']
corrected_model = OrderedDict({key: new_loaded_model[key] for key in t_dsnae.state_dict()})
t_dsnae.load_state_dict(corrected_model)
else:
t_dsnae.load_state_dict(torch.load(os.path.join(kwargs['model_save_folder'], 'm_t_dsnae.pt')))
except FileNotFoundError:
raise Exception("No pre-trained encoder")
return t_dsnae.shared_encoder, (dsnae_train_history, dsnae_val_history)
5.3 evaluation_utils.py
evaluation_utils.py(非全部函数)
import pandas as pd
from collections import defaultdict
import numpy as np
import torch
from sklearn.metrics import roc_auc_score, average_precision_score, accuracy_score, f1_score, log_loss, auc, precision_recall_curve
def model_save_check(history, metric_name, tolerance_count=5, reset_count=1):
"""
检查模型训练过程中某个度量指标(loss/distance)的历史记录,并根据指标的变化情况确定是否保存模型,以及是否停止训练。其中,tolerance_count和reset_count分别表示连续达到多少次指标变差的次数和重新计数的次数,用于控制停止训练的时机。如果度量指标以'loss'结尾,则使用更低的指标值进行比较,否则使用更高的指标值进行比较。最后,函数返回一个保存标志和一个停止标志,用于告知模型训练过程中是否需要保存模型和停止训练。
"""
save_flag = False
stop_flag = False
if 'best_index' not in history:
history['best_index'] = 0
if metric_name.endswith('loss'):
if history[metric_name][-1] <= history[metric_name][history['best_index']]:
save_flag = True
history['best_index'] = len(history[metric_name]) - 1
else:
if history[metric_name][-1] >= history[metric_name][history['best_index']]:
save_flag = True
history['best_index'] = len(history[metric_name]) - 1
if len(history[metric_name]) - history['best_index'] > tolerance_count * reset_count and history['best_index'] > 0:
stop_flag = True
return save_flag, stop_flag
5.4 pretrain_hyper_main.py
pretrain_hyper_main.py
import pandas as pd
import torch
import json
import os
import argparse
import random
import pickle
import itertools
import data
import data_config
import train_code_adv
import train_adae
import train_code_base
import train_coral
import train_dae
import train_vae
import train_ae
import train_code_mmd
import train_dsn
import train_dsna
def generate_encoded_features(encoder, dataloader, normalize_flag=False):
"""
:param normalize_flag:
:param encoder:
:param dataloader:
:return:
"""
encoder.eval()
raw_feature_tensor = dataloader.dataset.tensors[0].cpu()
label_tensor = dataloader.dataset.tensors[1].cpu()
encoded_feature_tensor = encoder.cpu()(raw_feature_tensor)
if normalize_flag:
encoded_feature_tensor = torch.nn.functional.normalize(encoded_feature_tensor, p=2, dim=1)
return encoded_feature_tensor, label_tensor
def load_pickle(pickle_file):
data = []
with open(pickle_file, 'rb') as f:
try:
while True:
data.append(pickle.load(f))
except EOFError:
pass
return data
def wrap_training_params(training_params, type='unlabeled'):
aux_dict = {k: v for k, v in training_params.items() if k not in ['unlabeled', 'labeled']}
aux_dict.update(**training_params[type])
return aux_dict
def safe_make_dir(new_folder_name):
if not os.path.exists(new_folder_name):
os.makedirs(new_folder_name)
else:
print(new_folder_name, 'exists!')
def dict_to_str(d):
return "_".join(["_".join([k, str(v)]) for k, v in d.items()])
def main(args, update_params_dict):
if args.method == 'dsn':
train_fn = train_dsn.train_dsn
elif args.method == 'adae':
train_fn = train_adae.train_adae
elif args.method == 'coral':
train_fn = train_coral.train_coral
elif args.method == 'dae':
train_fn = train_dae.train_dae
elif args.method == 'vae':
train_fn = train_vae.train_vae
elif args.method == 'vaen':
train_fn = train_vae.train_vae
elif args.method == 'ae':
train_fn = train_ae.train_ae
elif args.method == 'code_mmd':
train_fn = train_code_mmd.train_code_mmd
elif args.method == 'code_base':
train_fn = train_code_base.train_code_base
elif args.method == 'dsna':
train_fn = train_dsna.train_dsna
else:
train_fn = train_code_adv.train_code_adv
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gex_features_df = pd.read_csv(data_config.gex_feature_file, index_col=0)
with open(os.path.join('model_save/train_params.json'), 'r') as f:
training_params = json.load(f)
training_params['unlabeled'].update(update_params_dict)
param_str = dict_to_str(update_params_dict)
if not args.norm_flag:
method_save_folder = os.path.join('model_save', args.method)
else:
method_save_folder = os.path.join('model_save', f'{args.method}_norm')
training_params.update(
{
'device': device,
'input_dim': gex_features_df.shape[-1],
'model_save_folder': os.path.join(method_save_folder, param_str),
'es_flag': False,
'retrain_flag': args.retrain_flag,
'norm_flag': args.norm_flag
})
safe_make_dir(training_params['model_save_folder'])
random.seed(2020)
s_dataloaders, t_dataloaders = data.get_unlabeled_dataloaders(
gex_features_df=gex_features_df,
seed=2020,
batch_size=training_params['unlabeled']['batch_size'],
ccle_only=True
)
# start unlabeled training
encoder, historys = train_fn(s_dataloaders=s_dataloaders,
t_dataloaders=t_dataloaders,
**wrap_training_params(training_params, type='unlabeled'))
with open(os.path.join(training_params['model_save_folder'], f'unlabel_train_history.pickle'),
'wb') as f:
for history in historys:
pickle.dump(dict(history), f)
if __name__ == '__main__':
parser = argparse.ArgumentParser('ADSN training and evaluation')
parser.add_argument('--method', dest='method', nargs='?', default='code_adv',
choices=['code_adv', 'dsna', 'dsn', 'code_base', 'code_mmd', 'adae', 'coral', 'dae', 'vae',
'vaen', 'ae'])
train_group = parser.add_mutually_exclusive_group(required=False)
train_group.add_argument('--train', dest='retrain_flag', action='store_true')
train_group.add_argument('--no-train', dest='retrain_flag', action='store_false')
parser.set_defaults(retrain_flag=True)
train_group.add_argument('--pdtc', dest='pdtc_flag', action='store_true')
train_group.add_argument('--no-pdtc', dest='pdtc_flag', action='store_false')
parser.set_defaults(pdtc_flag=False)
norm_group = parser.add_mutually_exclusive_group(required=False)
norm_group.add_argument('--norm', dest='norm_flag', action='store_true')
norm_group.add_argument('--no-norm', dest='norm_flag', action='store_false')
parser.set_defaults(norm_flag=True)
args = parser.parse_args()
print(f'current config is {args}')
params_grid = {
"pretrain_num_epochs": [0, 100, 300],
"train_num_epochs": [100, 200, 300, 500, 750, 1000, 1500, 2000, 2500, 3000],
"dop": [0.0, 0.1]
}
if args.method not in ['code_adv', 'adsn', 'adae', 'dsnw']:
params_grid.pop('pretrain_num_epochs')
keys, values = zip(*params_grid.items())
update_params_dict_list = [dict(zip(keys, v)) for v in itertools.product(*values)]
for param_dict in update_params_dict_list:
main(args=args, update_params_dict=param_dict)